[Guilherme Parreira] | September 4, 2018
Olá pessoal, tudo bem?
Hoje irei conversar sobre um termo muito utilizado na estatística, mas que a interpretação/conceito costuma gerar dúvidas: o Intervalo de Confiança.
Antes de falar especificamente sobre o intervalo de confiança, é necessário introduzir alguns conceitos: população, amostra, estimadores pontuais e intervalares, além da distribuição amostral.
Caso
Vamos supor que estamos interessados em estimar o peso médio dos habitantes da cidade de Curitiba. Uma forma de fazer isso, seria realizar um censo e mensurar o peso de todos os habitantes da cidade. No entanto, realizar um censo demanda muito tempo e é de alto custo, pois estaríamos mensurando toda a população. Como alternativa, podemos coletar uma amostra para estimar o peso dos habitantes. O tamanho da amostra depende principalmente da variabilidade da variável e do tamanho da população, maiores detalhes estarão descritos em um próximo post :D.
Para esse estudo foi coletada uma amostra de 10,000 habitantes. Uma forma de resumir o peso dos indivíduos é a partir da média amostral. Note, que a amostra não forneçe o peso médio real dos habitantes da cidade de Curitiba, mas sim, um valor aproximado, pois não temos a informação de todos os habitantes. Caso tivéssemos toda a população, teríamos o valor de \(\mu\), o parâmetro populacional que a representa o peso média de todos os habitantes, ou seja, o peso médio real.
Distribuição amostral
Ao invés disso, temos uma amostra, e uma forma de se obter um valor que represente \(\mu\) seria através de um estimador pontual, que nesse caso é a média amostral \(\bar{X}\). Diferentes amostras de 10,000 habitantes cada resultariam em diferentes valores para a média amostral. O estudo da distribuição de \(\bar{X}\) é feita a partir da distribuição amostral (BUSSAB; MORETTIN, 2010). Não entrarei em detalhes técnicos aqui sobre a distribuição amostral, no entanto, ela garante que se os dados seguem uma distribuição normal, podemos estimar os parâmetros de média (\(\mu\)) e variância (\(\sigma^2\)) a partir dos seus estimadores amostrais \(\bar{X}\) e \(S^2\):
\[\bar{X} = \frac{\sum_{i=1}^{n}X_{i}}{n}\]
\[S^2 = \frac{\sum_{i=1}^{n}(X_{i} - \bar{X})^2}{n - 1}\]
em que:
- \(\bar{X}\) é a média amostral, estimador da média populacional;
- \(S^2\) é a variância amostral;
- \(n\) é o tamanho amostral;
Construção do intervalo de confiança
Note que esses estimadores retornam estimativas pontuais (apenas um valor) sobre o parâmetro de interesse. No entanto, ao selecionarmos uma amostra, estamos sujeitos ao erro amostral pois não temos a informação de toda a população. Dessa forma, o interessante seria obter um intervalo que representasse \(\bar{X}\), como forma de medir a variabilidade das amostras, e consequentemente saber o erro atribuído ao estimador. O nome desse intervalo é o intervalo de confiança. Um intervalo de confiança para o parâmetro \(\mu\) é obtido a partir da seguinte fórmula:
\[IC (\mu, 1-\alpha) = (\bar{X} - Z_{\alpha/2}\sqrt{\frac{\sigma^2}{n}} ; \bar{X} + Z_{\alpha/2}\sqrt{\frac{\sigma^2}{n}})\]
Em que:
- \(\mu\) é o parâmetro para o qual queremos construir o intervalo, que nesse caso, é a média populacional;
- \(\alpha\) é o nível de significância, ou erro do tipo I, normalmente fixado em 0,05 (5%);
- \(1 - \alpha\) representa o grau de confiança do intervalo (\(\gamma\)), normalmente fixado em 0,95 (95% de confiança);
- \(\bar{X}\) é a média amostral, estimador da média populacional;
- \(Z_{\alpha/2}\) é o quantil da distribuição normal que configura um intervalo de \(\gamma\)% de confiança;
- \(\sigma^2\) é a variância populacional;
- \(n\) é o tamanho amostral;
No entanto, em situações práticas normalmente não sabemos o valor de \(\sigma^2\), dessa forma, utilizamos o valor de \(S^2\) para estimá-lo. Dessa forma, obtém-se o seguinte intervalo de confiança:
\[IC (\mu, 1-\alpha) = (\bar{X} - t_{\alpha/2}\sqrt{\frac{S^2}{n}} ; \bar{X} + t_{\alpha/2}\sqrt{\frac{S^2}{n}})\]
Ao aplicar a raiz quadrada em \(S^2\) obtemos o valor do desvio padrão:
\[IC (\mu, 1-\alpha) = (\bar{X} - t_{\alpha/2}\frac{s}{\sqrt{n}} ; \bar{X} + t_{\alpha/2}\frac{s}{\sqrt{n}})\]
em que \(t_{\alpha/2}\) é o quantil da distribuição t de Student que configura um intervalo de \((1 - \alpha)\)% de confiança;
A utilização da distribuição Z é válida quando conhecemos o desvio padrão populacional. Quando o desvio padrão for desconhecido, utilizamos a distribuição t de Student.
Exemplo
Voltando ao exemplo, vamos supor que o peso dos habitantes seguem uma distribuição normal com desvio padrão conhecido e igual a 10. Sendo assim, iremos gerar 25 amostras de tamanho 10,000 cada (isto é, fazer 25 estudos diferentes com o mesmo tamanho amostral), de uma distribuição Normal com média 70 e desvio padrão igual a 10. Em seguida, irei calcular a média amostral e o intervalo de confiança para a média com 95% de confiança para cada uma das 25 amostras (estudos). O próximo gráfico ilustra os intervalos para cada amostra:
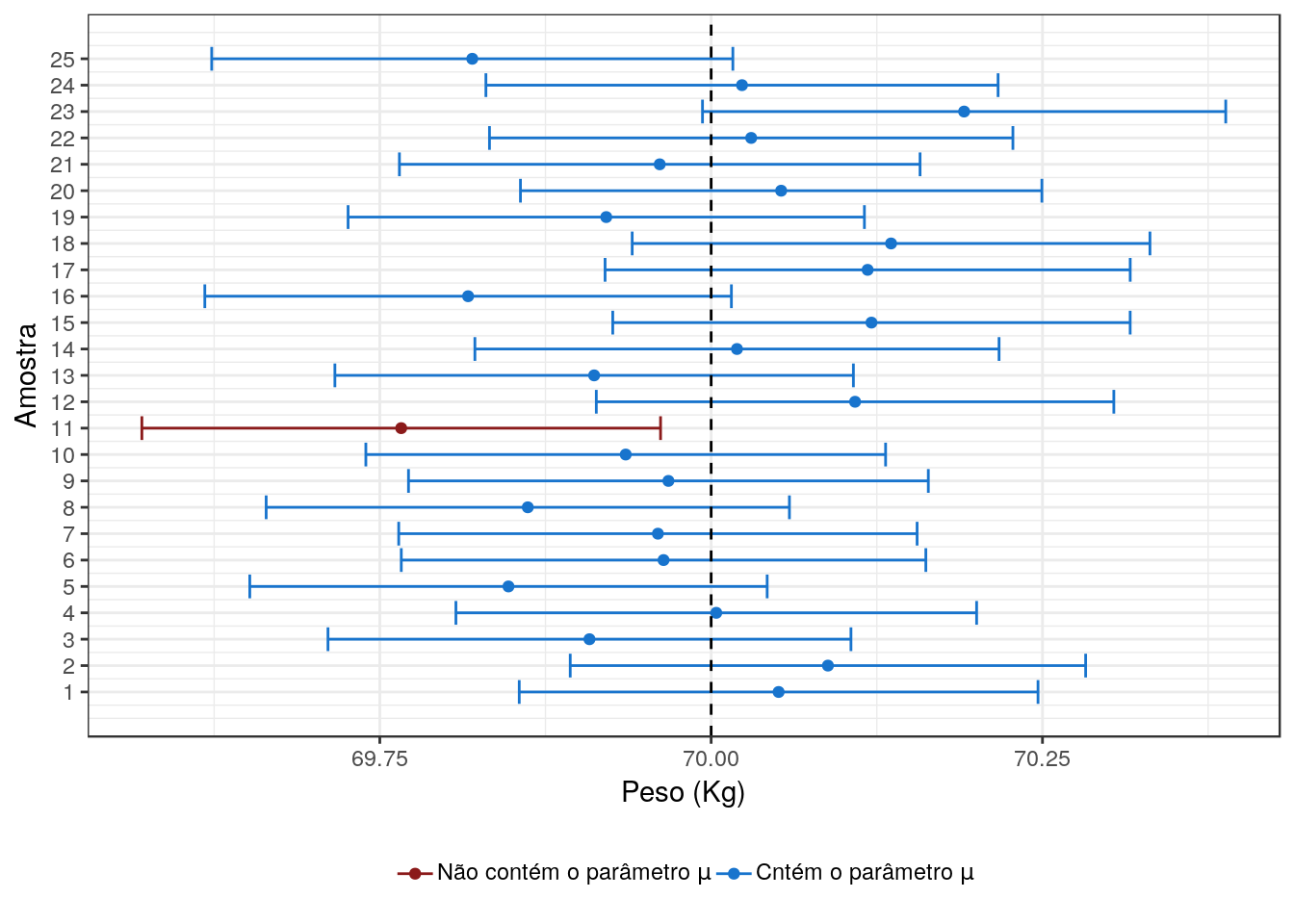
No eixo x são apresentados os valores da média amostral, no eixo y a representação de cada amostra e a linha tracejada na vertical representa o verdadeiro valor da média populacional (\(\mu = 70\)). Na 1ª amostra, o peso médio amostral foi igual a 70.05 (representado pelo ponto) com intervalo inferior igual a 69.86 e intervalo superior igual a 70.25. A interpretação do intervalo de confiança para esse estudo é feita da seguinte forma: caso esse estudo fosse repetido um grande número de vezes, esperasse que em 100*(\(1 - \alpha\))% deles, o intervalo de confiança conteria o verdadeiro valor do parâmetro de interesse (\(0 < \alpha < 1\)).
Nesse exemplo é possível verificar se a interpretação do intervalo de confiança faz sentido. Como nesse caso, nós repetimos o mesmo estudo 25 vezes, e para um intervalo de 95% de confiança, esperasse que 24 (\(25*95\%\)) deles produzam intervalos de confiança que contenham o verdadeiro valor da média (\(\mu\)). Esse é justamente o comportamento que aconteceu. Note que 24 estudos (em cor azul) obtiveram intervalos de confiança que contém o verdadeiro valor do peso dos habitantes, enquanto que apenas 1 não conteve o verdadeiro valor de \(\mu\), representado pelo intervalo de confiança de cor vermelha.
Isso acontece, pois, estamos trabalhando com uma amostra, e sendo assim, sempre temos um erro associado a ela, mesmo que a amostra seja aleatória e todos os procedimentos de coleta sejam respeitados.
É isso aí pessoal! Esse post definiu, exemplificou e interpretou o intervalo de confiança. Ainda, existem situações que são utilizadas diferentes distribuições para a variável de interesse (como a t de Student), nível de confiança, mas a interpretação permanece a mesma.
Até a próxima!! E boa pesquisa!
Referências
BUSSAB, W. DE O.; MORETTIN, P. A. Estatística básica. Traducao. [s.l.] Saraiva, 2010.