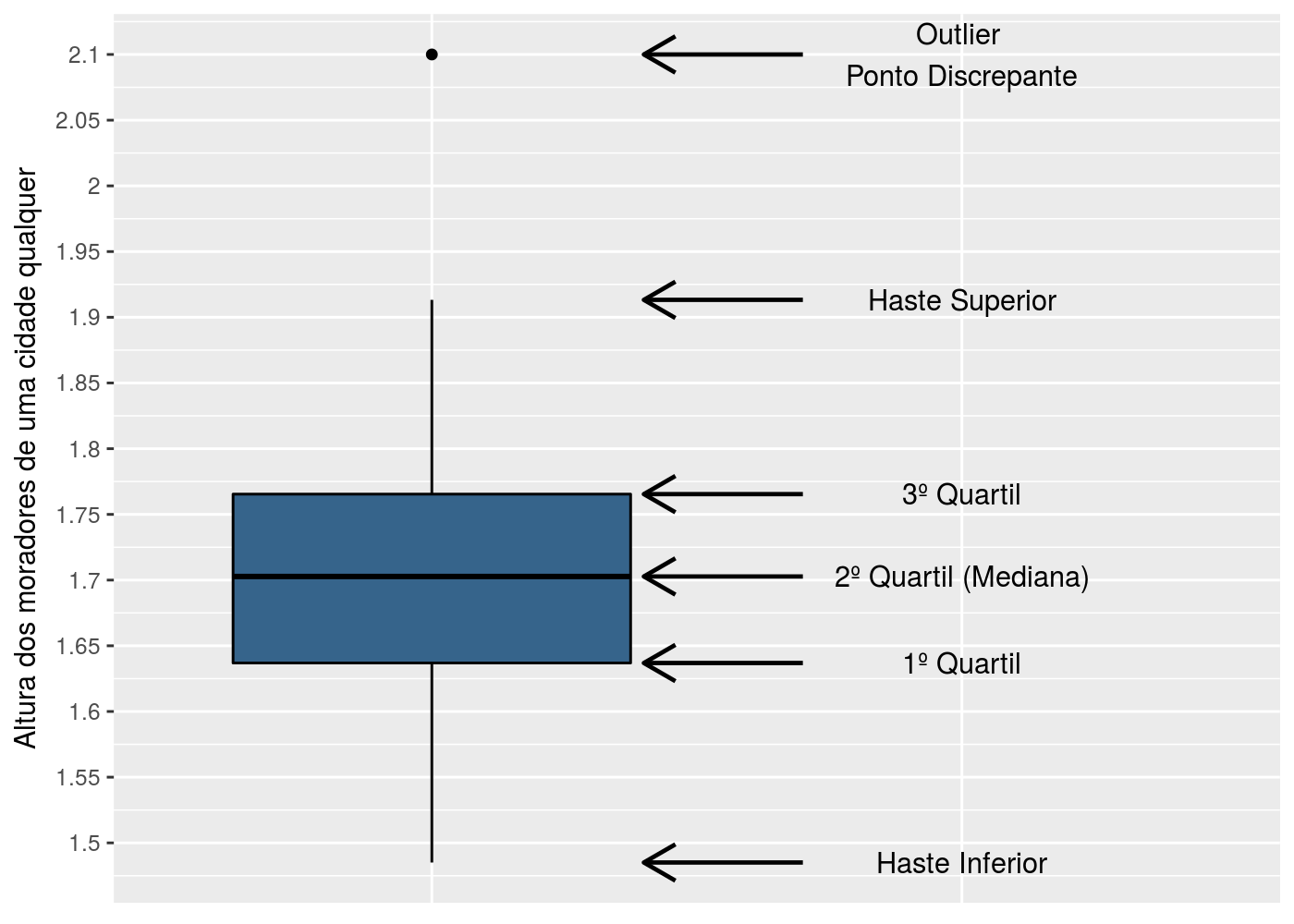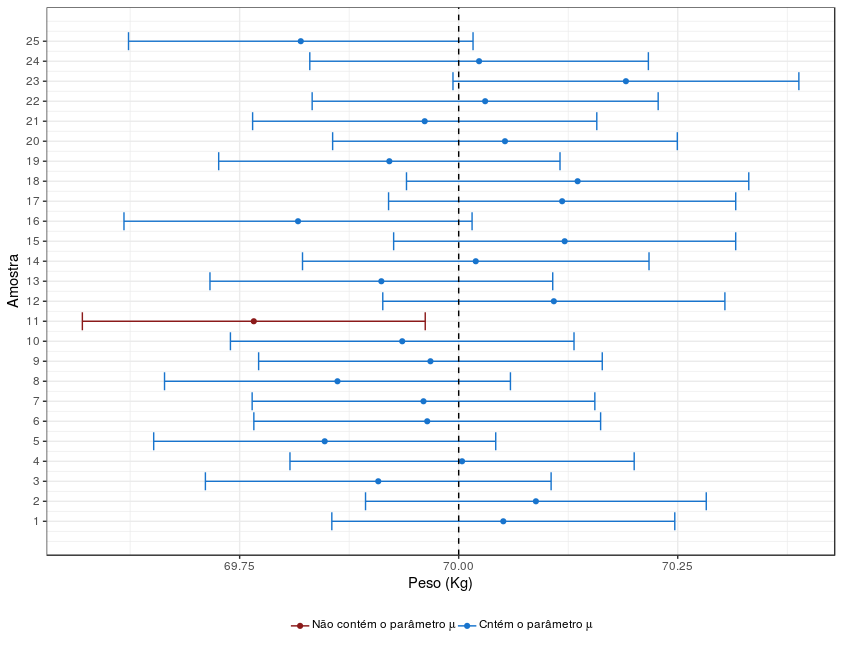
Intervalo De Confiança
Olá pessoal, tudo bem? Hoje irei conversar sobre um termo muito utilizado na estatística, mas que a interpretação/conceito costuma gerar dúvidas: o Intervalo de Confiança. Antes de falar especificamente sobre o intervalo de confiança, é necessário introduzir alguns conceitos: população, amostra, estimadores pontuais e intervalares, além da distribuição amostral. Caso Vamos supor que estamos interessados em estimar o peso médio dos habitantes da cidade de Curitiba. Uma forma de fazer isso, seria realizar um censo e mensurar o peso de todos os habitantes da cidade.